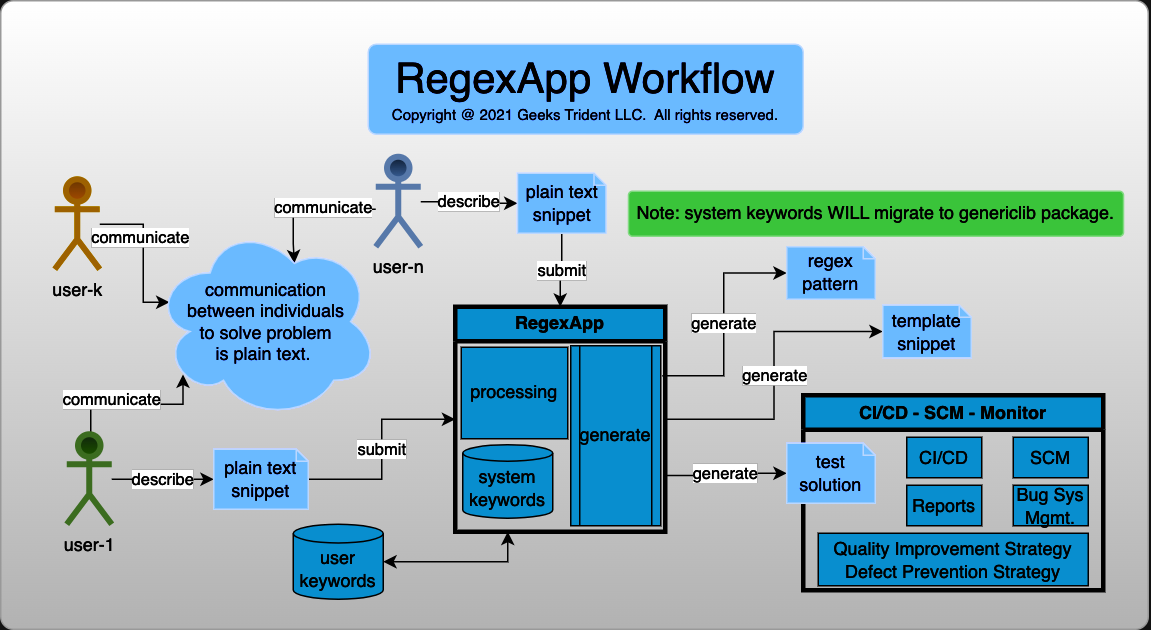
Welcome to RegexApp Docs
RegexApp is a closed source Python package that is used to help individuals to generate Python regular expression pattern by using plain text. RegexApp offers two licenses: Non-Commercial-Use License and Commercial-Use License
Non-Commercial-Use License
| Development Status | ALPHA |
|---|---|
| Availability | Online App by www.geekstrident.com |
| Installation | N/A |
| Cost | Free of Charge |
| Ad-Free | With Ad |
| Test Solution | N/A |
| Tech Support | N/A |
| Integration | N/A |
Commercial-Use License
| Development Status | ALPHA |
|---|---|
| Availability |
Online or Offline App by
CLIENT DEPLOYMENT
or
Online App by PARTNER / THIRD-PARTY services |
| Installation | Github or Offline-package |
| Cost | Cost per Strategy |
| Ad-Free | YES |
| Test Solution | YES |
| Tech Support | YES |
| Integration | YES |
Benefit of Using RegexApp
Mitigating Human Error
Unintended Action Based Error (Slip)
Let's use typo error to demonstrate a process of mitigating this type of error. Assuming user1 wants to create a regex pattern that can search multiple digits following by plus sign in text. For example,
User1 really wants to create a below pattern
Indeed, user1 accidentally creates a pattern without a second back flash
Thus, a commit code without unit test might be a result of
Assuming RegexApp is available. User1 needs to translate the requirements to a format that RegexApp can understand. For this case, multiple digits are altered values. RegexApp's digit keyword is an equivalent representation of this interpretation. Plus sign is fixed value. It's a regular text, just leave it as is.
If user pattern is created
a result of generated pattern from RegexApp can be
Unintended Memory Based Error (Lapse)
Let's use distraction to understand this type of error and find possible way to mitigate it. Assuming user1 is given an assignment to create a regex pattern to match IPv4 address in text.
User1 creates a pattern with testing
Another day, user2 reuses user1's pattern. After testing with new data, user2 sees unexpected outcome. User2 forwards this issue user1.
After studied problem, user1 explain
Intended Error
This type of error can be
- Intended Rule Based Mistake
- Intended Knowledge Based Mistake
- Human Use Error
- Latent Error
- ...
and, the practical approach of software development process are
- Quality Assurance
- Collaboration
- Risk Management
- Security
- Reliability
- Consistency
- Proficiency
- Scalability
- Extensibility
- Portability
- Continuous Improvement
- ...
RegexApp needs to collaborate with other services to build high-quality software products.
Reusing Resource
Reusing Verified Solution
The main purpose of RegexApp let individuals to reuse the verified solution as many as possible with confident so that individuals can produce the quality work and reduce waste or duplication. For example, developer1 is given an assignment to create an IPv4 regular expression pattern. Assuming developer1 creates IPv4 pattern with some testings,
Developer1 thinks this pattern should work fine for matching or capturing IPv4 address, developer1 decides to implement it to code base. After a while, developer1 receives feedback from end-users that IPv4 address pattern captures unexpected "2.3.5.320" value. Developer1 performs RCA (i.e., Root Cause Analysis) and finds out a problem such as
Technically, "\\d{1,3}(\\.\\d{1,3}){3}" should match IPv4 address and <major>.<minor>.<build>.<revision>. Developer1 decides to resolve this problem to avoid any matching non-IPv4-address issue.
Step #1: Analyzing Octet
Step #2: Creating Variables for Analyzing Cases
Step #3: Simplifying Cases and Building Octet Pattern
Step #4: Building IPv4 Address Pattern
Step #5: Preparing Resources for Verification
Step #6: Creating Test Function for Verifying IPv4 Address Pattern
Step #7: Executing Test
Assuming this quality rework MIGHT take developer1 one day of work or more. If developer1 or team's developer1 doesn't have strategy for reusing this quality work, other developer might WASTE some work hours and MIGHT create other issue. However, if RegexApp is available, developer1 can MANUALLY edit ipv4_address_with_validation solution if RegexApp is OFFLINE version.
Adding-Solution #1: Preparing Solution
Adding-Solution #2: Appending Solution
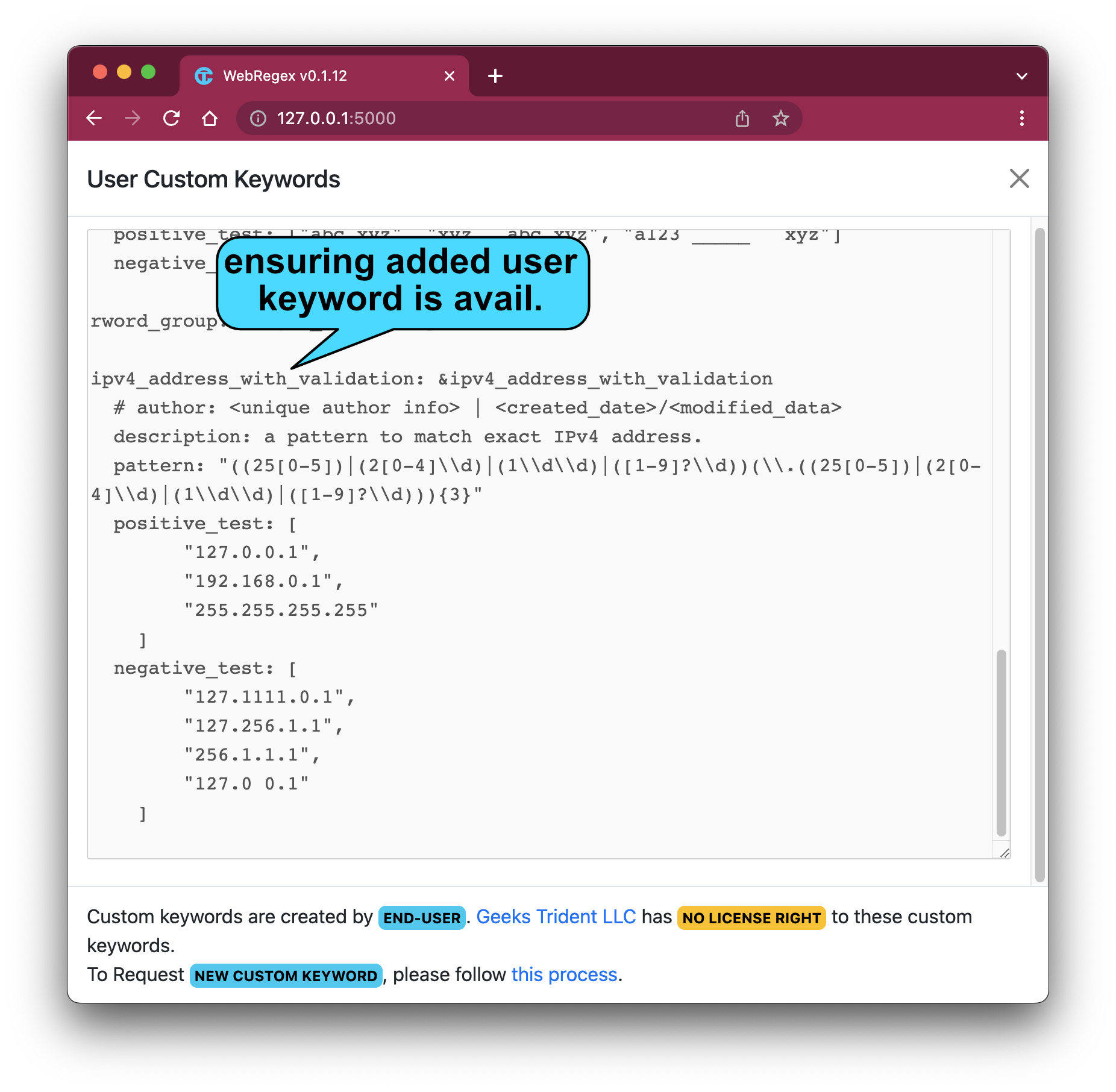
Depending on OS and RegexApp name, assuming OS is macOS and app name is RegexPro. Manually appending solution to this "~/.geekstrident/regexpro/user_references.yaml" file. For example,
Adding-Solution #3: Restarting WebRegex App and Verifying User Custom Keywords
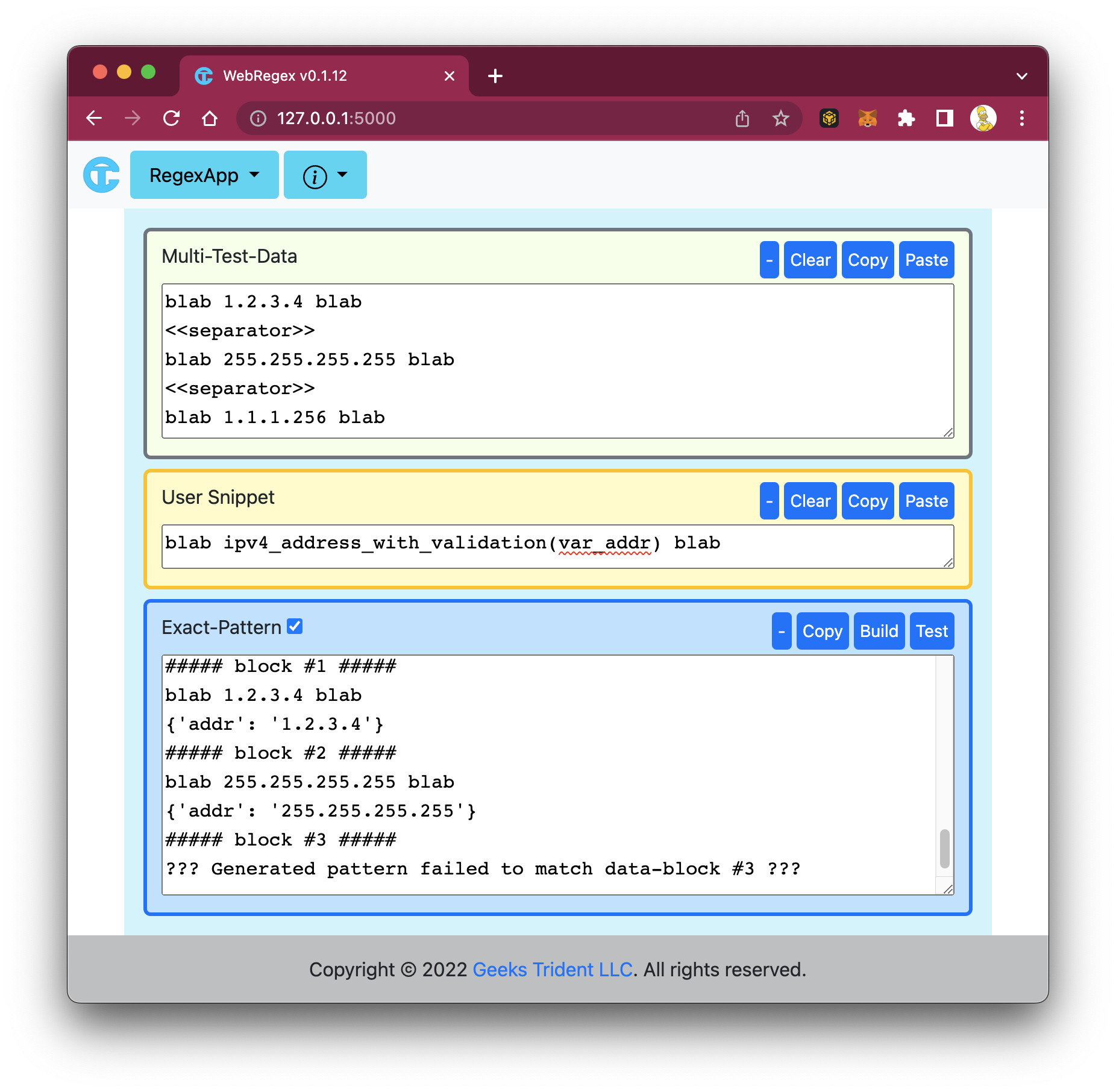
Adding-Solution #4: Executing Some Tests for Confirmation
Adding-Solution #5: Informing Development Teams or Other Groups
Reusing Test Data
RegexApp Builder - Differential
Differential feature lets end-user to build generic snippet or regex pattern based on multiple different data where format of data should be a combination of <UNCHANGED-TEXT> and <CHANGED-TEXT>. Assuming end-user wants to capture color value in this data set where differential pattern of this data set is
For example, assuming end-user wants to capture color value in this data set
Iteration #1: Preparing Multiple Different Test Data
Copy each data to and paste to Test-Data of Builder - Differential. RegexApp should create
or just manually edit <<separator>> on top to let RegexApp to interpret data set as multiple line-test-data.
Iteration #2: Building Solution From Test Data and Testing
Iteration #3: Modifying Generated Snippet and Testing
RegexApp Builder - Category
Category feature lets end-user to build generic snippet or regex pattern based on single data where format of data should be
For example, assuming end-user wants to capture meats, fruits, and drinks values in this data set
Iteration #1: Preparing Test Data
Iteration #2: Building Solution From Test Data and Testing
Iteration #3: Modifying Generated Snippet and Testing If Necessary
RegexApp Builder - Iteration
Iteration feature helps end-users to understand how generic snippet or regex pattern get constructed. It uses test data to generate interaction protocol. Individuals need to interact with interaction protocol to build a solution.
Iteration #1: Building Interaction Protocol
Assuming test data is
Click build button on Builder - Iteration, WebRegex should generate this interaction protocol
Iteration #2: Modifying Interaction Protocol
Interaction protocol has two group of keywords: Operating Keywords and Editing Keywords
Iteration #2-1: Modifying Interaction Protocol - Assigning Capturing Variable
Assuming end-user wants to capture temperature value and temperature unit
The new generated snippet should be
The new generated pattern should be
Iteration #2-2: Modifying Interaction Protocol - Applying Matching
Assuming a first word of test data can be either
Use keep(0) or kvar=v0 to build matching. The new generated snippet should be
The new generated pattern should be
However, if first word of test data can be a value or empty, use Kvar=v0 to solve it
Iteration #2-3: Modifying Interaction Protocol - Joining Variables
Assuming end-user wants to join temperature and unit variables into one variable and name it as temperature_unit
Step 1: Applying action(temperature,unit-join) to perform join
Step 2: Applying cvar=temperature_unit to perform capturing
Iteration #2-4: Modifying Interaction Protocol - Splitting Variable
Assuming test data is
and the generated interaction protocol is
Assuming end-user wants to capture 123 value and store in flag variable
Step 1: Performing split operation
Step 1: Performing capture operation
RegexApp Builder - Free Style
SHOULD BE AVAILABLE in BETA VERSION
RegexApp Builder - Designing
SHOULD BE AVAILABLE in BETA VERSION
Low Learning Curve
RegexApp employs principle of least effort to boost individuals to quickly recognize problem and confidently build solution. Builder features are generated GENERIC solution which is based on human analogy expression combining generic decision making selection. For example,
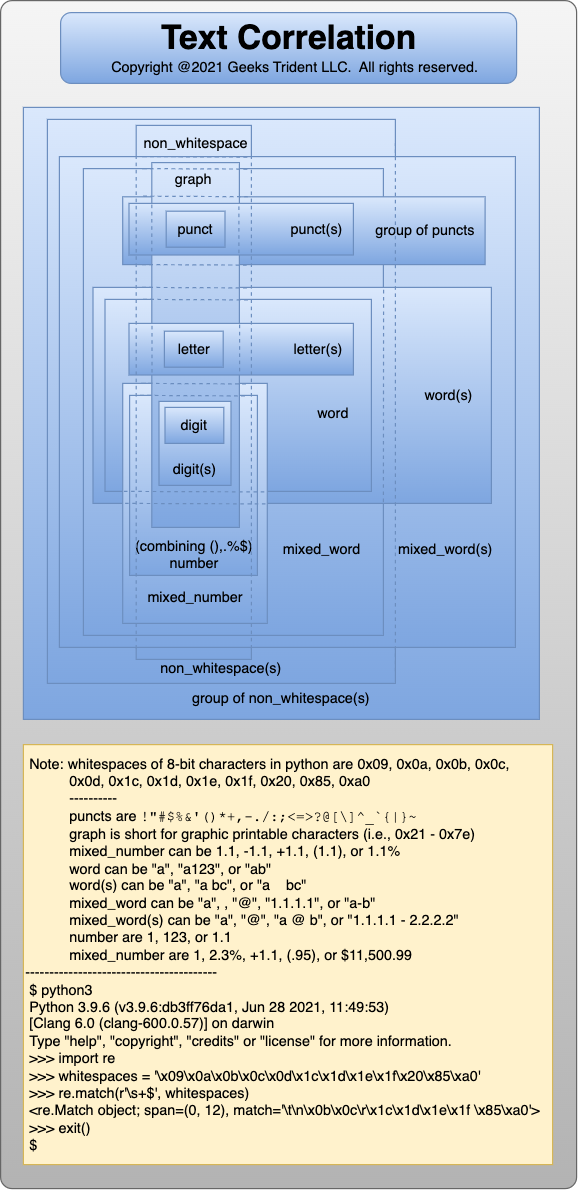
Furthermore, RegexApp provide intuitive method to play with data to produce the solution. For example, assuming end-user is given an assignment to parse output of command line that contains interface name, flag value, interface status, interface info, and mtu value.

Step 1: Reformatting Data to General Human Readable Form
Step 2: Separating Any Combining Fields
Step 3: Creating New Test Data by Substitution
Step 4: Preparing Multi Test Data For Builder - Differential Feature
Step 5: Building Solution and Testing
Step 6: Modifying Appropriate Variable Names
Step 7: Restoring Generated Snippet to Original Format and Testing
Step 8: Intuitively Communicating with Other
Assuming below generated snippet and generated pattern are final solution
However, reviewer might disagree below test result because reviewer thinks that interface_status should be "UP", "DOWN", or "ERROR", but it CAN NOT be broadcast.
If end-user uses generated pattern to discuss the unexpected result with data owner, they might need more time to find the root cause.
However, if end-user uses general form or generated snippet to discuss the unexpected result with reviewer or data owner,
data owner or reviewer might quickly make feedback such as
End-user can improve solution by reworking snippet to deliver expected result such as
Furthermore, data owner or reviewer adds additional feedback such as,
End-user continues to improve solution such as
Step 9: Submitting Finally Result For Reviewing
Drawback
The main purpose of RegexApp application is to simplify a process of creating regular expression pattern to improve code quality. Most features are designed to solve specific problem relating to human error, wasting resources, or complex training. Experience individuals with solid regular expression problem-solving knowledge who rely too much on RegexApp MUST BE a result of lowering regular expression creativity over time.
Understanding RegexApp Keywords
There are three types of keywords: reserved keyword, system keywords, and user keywords. These keywords associate with keyword arguments to enhance matching or capturing capacity.
Reserved Keywords
- start
- an indicator keyword to generate regex pattern to match at the beginning of string. Its keyword arguments are: space, spaces, ws, whitespace, or whitespaces.
- Usage
- start() or start(ws) start(space) or start(spaces) start(whitespace) or start(whitespaces)
- Example
-
start()
should generate
"^"
start(space) should generate "^ *"
start(spaces) should generate "^ +"
start(ws) should generate r"^\s*"
start(whitespace) should generate r"^\s*"
start(whitespaces) should generate r"^\s+"
- end
- an indicator keyword to generate regex pattern to match at the end of string. Its keyword arguments are: space, spaces, ws, whitespace, or whitespaces.
- Usage
- end() or end(ws) end(space) or end(spaces) end(whitespace) or end(whitespaces)
- Example
-
end()
should generate
"$"
end(space) should generate " *$"
end(spaces) should generate " +$"
end(ws) should generate r"\s*$"
end(whitespace) should generate r"\s*$"
end(whitespaces) should generate r"\s+$"
- data
- an matching or capturing keyword to generate regex pattern to match or to capture raw data. Its keyword arguments should be similar to system keyword arguments.
- Usage
- data(<raw_data>) data(var_<name>, <raw_data>, <other_arguments>)
- Example
-
data(..) data(var_v1, ++>passed, word_bound_right)
should generate
r"\.\. (?P<v1>(\+\+>passed)\b)"
>>> >>> import re >>> test_data = ".. ++>passed" >>> # assuming generated pattern is >>> pattern = r"\.\. (?P<v1>(\+\+>passed)" >>> match = re.search(pattern, test_data) >>> print(match) <re.Match object; span=(0, 12), match='.. ++>passed'> >>> print(match.groupdict()) {'v1': '++>passed'} >>>
- end
- an matching or capturing keyword to generate regex pattern to match or to capture predefined symbols. Its keyword arguments should be similar to system keyword arguments.
- Usage
- symbol(name=<symbol_name>) symbol(var_<name>, name=<symbol_name>, <other_arguments>)
- Example
-
start() symbol(name=dot, 5_occurrences) symbol(name=hyphen, at_least_3_occurrence) end()
should generate
r"^\.{5} +-{3,}$"
The generated pattern should match this "..... ----------" data.
The generated pattern should not match this "........ ----------" data.
System Keywords
- Usage
- <keyword>(var_<name>, <other_data,...>, or_empty, or_<other_keywords>, <keyword_arguments>)
- Example #1
-
digits()
is a format of
<keyword>()which should match at least one numeric.
Its generated pattern is r"\d+".
- Example #2
-
digits(N/A)
is a format of
<keyword>(<other_data,...>)which should match at least one numeric or N/A data.
Its generated pattern is r"\d+|N/A".
- Example #3
-
digits(var_v1, N/A)
is a format of
<keyword>(var_<name>, <other_data,...>)which should capture at least one numeric or N/A data, and then store in v1 variable.
Its generated pattern is r"(?P<v1>\d+|N/A)".
- Example #4
-
digits(var_v1, or_empty)
is a format of
<keyword>(var_<name>, or_empty)which should capture at least one numeric or empty data and then store in v1 variable.
Its generated pattern is r"(?P<v1>\d+|)".>>> import re >>> >>> # start() Food: word(var_food, or_empty) Total: digits(var_total, N/A) end() >>> # Assuming pattern is generated from above user data pattern >>> pattern = r"^Food:\s*(?P<food>[a-zA-Z][a-zA-Z0-9]*|) +Total: (?P<total>\d+|N/A)$" >>> >>> test_data = """ ... Food: Mango Total: 159 ... Food: Total: N/A ... """.strip() >>> >>> for line in test_data.splitlines(): ... match = re.search(pattern, line) ... if match: ... print(match.groupdict()) ... {'food': 'Mango', 'total': '159'} {'food': '', 'total': 'N/A'} >>>
- Example #5
-
ipv4_addr(var_addr, or_mac_addr)
is a format of
<keyword>(var_<name>, or_<other_keyword>)which should capture either IPv4 address or MAC address, and then store in addr variable.
Its generated pattern is r"^Address: (?P<addr>\d{1,3}([.]\d{1,3}){3}|([0-9a-fA-F]{2}([: -][0-9a-fA-F]{2}){5})) *$".>>> # start() Address: ipv4_addr(var_addr, or_mac_addr) end(space) >>> # Assuming pattern is generated from above user data pattern >>> pattern = r"^Address: (?P<addr>\d{1,3}([.]\d{1,3}){3}|([0-9a-fA-F]{2}([: -][0-9a-fA-F]{2}){5})) *$" >>> >>> test_data = """ ... Address: 192.168.1.1 ... Address: AA:11:BB:22:CC:33 ... """.strip() >>> >>> import re >>> >>> for line in test_data.splitlines(): ... match = re.search(pattern, line) ... if match: ... print(match.groupdict()) ... {'addr': '192.168.1.1'} {'addr': 'AA:11:BB:22:CC:33'} >>>
- Example #6
-
letters(var_v1, 5_occurrence)
is a format of
<keyword>(var_<name>, <keyword_arguments>)which should match at least one numeric.
Its generated pattern is r"(?P<v1>[a-zA-Z]{5})".
User Keywords
These keywords are created by users and stored in ~/.geekstrident/regexpro/user_references.yaml file on deployed system. Keywords MUST NOT DUPLICATE reserved and system keywords. Future version should provide an option to let users to store or to access user keyword by using database. The usage of user keywords is similar to the usage of system keywords
Keyword Arguments
Categories: capturing, alternation, repetition, occurrences, group-occurrences, word-bound, head, tail, and to-do-list.
- var_<name>
-
encapsulate keyword pattern with (?P<name>...). It should let regex store matching data to variable.
word(var_v1) should generate r"(?P<v1>[a-zA-Z][a-zA-Z0-9]*)" and store matching word to v1 variable.
- or_empty
-
join keyword pattern and empty string with
|
separator, and then encapsulate result with parenthesis, i.e.,
(...|).
It should let regex match zero or pattern.
word(or_empty) should generate r"([a-zA-Z][a-zA-Z0-9]*|)" that should match a word or an empty string.
- or_<other_keyword>
-
join keyword pattern and other-keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(...|...).
It should let regex match either keyword pattern or other keyword pattern.
time(or_number, format4) should generate r"(\d{2}:\d{2})|((\d+)?[.]?\d+)" that should match a number or time value of format 4 HH:MM.
- or_<datum>
<datum> -
join keyword pattern and datum with
|
separator.
Case 1: no enclosed parenthesis if data is singular form, i.e.,...|data1|data2|data_n.
digits(or_n/a, or_null, or_none) should generate r"(\d+)|n/a|null|none".
digits(n/a, null, none) should generate r"(\d+)|n/a|null|none".
Case 2: with enclosed parenthesis if data is plural form, i.e., (...|(data 1)|data2|data_n).
digits(or_n/a, or_not applicable) should generate r"((\d+)|n/a|(not applicable))".
digits(n/a, not applicable) should generate r"((\d+)|n/a|(not applicable))".
- or_repeat_k_space
or_k_space -
join
( {k})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {k})|...).
word(var_v1, or_repeat_5_space) should generate r"(?P<v1>( {5})|([a-zA-Z][a-zA-Z0-9]*))".
word(var_v1, or_5_space) should generate r"(?P<v1>( {5})|([a-zA-Z][a-zA-Z0-9]*))".
- or_repeat_m_n_space
-
join
( {m,n})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {m,n})|...).
word(var_v1, or_repeat_2_5_space) should generate r"(?P<v1>( {2,5})|([a-zA-Z][a-zA-Z0-9]*))".
- or_repeat__n_space
or_at_most_n_space -
join
( {,n})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {,n})|...).
word(var_v1, or_repeat__5_space) should generate r"(?P<v1>( {,5})|([a-zA-Z][a-zA-Z0-9]*))".
word(var_v1, or_at_most_5_space) should generate r"(?P<v1>( {,5})|([a-zA-Z][a-zA-Z0-9]*))".
- or_repeat_m__space
or_at_least_m_space -
join
( {m,})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {m,})|...).
word(var_v1, or_repeat_2__space) should generate r"(?P<v1>( {2,})|([a-zA-Z][a-zA-Z0-9]*))".
word(var_v1, or_at_least_5_space) should generate r"(?P<v1>( {2,})|([a-zA-Z][a-zA-Z0-9]*))".
- or_either_repeat_k_space
or_either_k_space -
join
( {k})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {k})| *... *).
word(var_v1, or_either_repeat_5_space) should generate r"(?P<v1>( {5})|( *[a-zA-Z][a-zA-Z0-9]* *))".
word(var_v1, or_either_5_space) should generate r"(?P<v1>( {5})|( *[a-zA-Z][a-zA-Z0-9]* *))".
- or_either_repeat_m_n_space
-
join
( {m,n})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {m,n})| *... *).
word(var_v1, or_either_repeat_2_5_space) should generate r"(?P<v1>( {2,5})|( *[a-zA-Z][a-zA-Z0-9]* *))".
- or_either_repeat__n_space
or_either_at_most_n_space -
join
( {,n})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {,n})| *... *).
word(var_v1, or_either_repeat__5_space) should generate r"(?P<v1>( {,5})|( *[a-zA-Z][a-zA-Z0-9]* *))".
word(var_v1, or_either_at_most_5_space) should generate r"(?P<v1>( {,5})|( *[a-zA-Z][a-zA-Z0-9]* *))".
- or_either_repeat_m__space
or_either_at_least_m_space -
join
( {m,})
and keyword pattern with
|
separator, and then encapsulate result with parenthesis, i.e.,
(( {m,})| *... *).
word(var_v1, or_either_repeat_2__space) should generate r"(?P<v1>( {2,})|( *[a-zA-Z][a-zA-Z0-9]* *))".
word(var_v1, or_either_at_least_5_space) should generate r"(?P<v1>( {2,})|( *[a-zA-Z][a-zA-Z0-9]* *))".
- repeat_k
-
append {k} to keyword pattern which transform to match exact k-time.
letter(var_v1, repetition_5) should generate r"(?P<v1>[a-zA-Z]{5})".
- repeat_m _n
-
append {m,n} to keyword pattern which transform to match at least m-time and at most n-time.
letter(var_v1, repetition_2_5) should generate r"(?P<v1>[a-zA-Z]{2,5})".
- repeat__n
-
append {,n} to keyword pattern which transform to match at most n-time.
letter(var_v1, repetition__5) should generate r"(?P<v1>[a-zA-Z]{,5})".
- repeat_m_
-
append {m,} to keyword pattern which transform to match at least m-time.
letter(var_v1, repetition_2_) should generate r"(?P<v1>[a-zA-Z]{2,})".
- k_occurrence
-
if k = 0, append ? to keyword pattern which transform to match zero or one matching.
if k = 1, is to match itself.
if k > 1, append {k} to keyword pattern which transform to match k-times.
letter(var_v1, 0_occurrence) should generate r"(?P<v1>[a-zA-Z]?)".
letter(var_v1, 1_occurrence) should generate r"(?P<v1>[a-zA-Z])".
letter(var_v1, 5_occurrence) should generate r"(?P<v1>[a-zA-Z]{5})".
- 0_or_1_occurrence
-
append
?
to keyword pattern which transform to match zero or one.
letter(var_v1, 0_or_1_occurrence) should generate r"(?P<v1>[a-zA-Z]?)".
- k_or_more_occurrence
-
if k = 0, append * to keyword pattern which transform to match zero or more matching.
if k = 1, append + to keyword pattern which transform to match at least one matching.
if k > 1, append {k,} to keyword pattern which transform to match at least k-times.
letter(var_v1, 0_or_more_occurrence) should generate r"(?P<v1>[a-zA-Z]*)".
letter(var_v1, 1_or_more_occurrence) should generate r"(?P<v1>[a-zA-Z]+)".
letter(var_v1, 3_or_more_occurrence) should generate r"(?P<v1>[a-zA-Z]{3,})".
- at_least_m_occurrence
-
if m = 0, append * to keyword pattern which transform to match zero or more matching.
if m >= 1, append {m,} to keyword pattern which transform to match at least m-times.
letter(var_v1, at_least_0_occurrence) should generate r"(?P<v1>[a-zA-Z]*)".
letter(var_v1, at_least_3_occurrence) should generate r"(?P<v1>[a-zA-Z]{3,})".
- at_most_n_occurrence
-
if n = 0, append ? to keyword pattern which transform to match zero or one matching.
if n >= 1, append {,n} to keyword pattern which transform to match at most n-times.
letter(var_v1, at_most_0_occurrence) should generate r"(?P<v1>[a-zA-Z]?)".
letter(var_v1, at_most_8_occurrence) should generate r"(?P<v1>[a-zA-Z]{,8})".
- k_phrase_occurrence
k_group_occurrence -
if k = 0, append ( ...)? or ( +...)? to keyword pattern which transform to match one or two matching.
if k = 1, append ( ...) or ( +...) to keyword pattern which transform to match exact two matching.
if k > 1, append ( ...){k,} or ( +...){k,} to keyword pattern which transform to match exact (k + 1) matching.
word(0_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*)?".
word(0_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*)?".
word(1_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*)".
word(1_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*)".
word(5_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*){5}".
word(5_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*){5}".
- 0_or_1_phrase_occurrence
0_or_1_group_occurrence -
append ( ...)? or ( +...)? to keyword pattern which transform to match one or two matching.
word(0_or_1_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*)?".
word(0_or_1_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*)?".
- k_or_more_phrase_occurrence
k_or_more_group_occurrence -
if k = 0, append ( ...)* or ( +...)* to keyword pattern which transform to match at least one matching.
if k = 1, append ( ...)+ or ( +...)+ to keyword pattern which transform to match at least two matching.
if k > 1, append ( ...){k,} or ( +...){k,} to keyword pattern which transform to match at least (k + 1) matching.
word(0_or_more_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*)*".
word(0_or_more_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*)*".
word(1_or_more_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*)+".
word(1_or_more_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*)+".
word(5_or_more_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*){5,}".
word(5_or_more_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*){5,}".
- at_least_m_phrase_occurrence
at_least_m_group_occurrence -
if m = 0, append ( ...)* or ( +...)* to keyword pattern which transform to match at least one matching.
if m >= 1, append ( ...){m,} or ( +...){m,} to keyword pattern which transform to match at least (m + 1) matching.
word(at_least_0_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*)*".
word(at_least_0_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*)*".
word(at_least_5_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*){5,}".
word(at_least_5_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*){5,}".
- at_most_n_phrase_occurrence
at_most_n_group_occurrence -
if n = 0, append ( ...)? or ( +...)? to keyword pattern which transform to match at most one or two matching.
if n >= 1, append ( ...){,n} or ( +...){,n} to keyword pattern which transform to match at most (n + 1) matching.
word(at_most_0_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*)?".
word(at_most_0_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*)?".
word(at_most_5_phrase_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( [a-zA-Z][a-zA-Z0-9]*){,5}".
word(at_most_5_group_occurrence) should generate r"[a-zA-Z][a-zA-Z0-9]*( +[a-zA-Z][a-zA-Z0-9]*){,5}".
- word_bound_left
-
prepend \b to the beginning of keyword pattern. It should let regex perform word bound on left matching.
word(word_bound_left) should generate r"\b[a-zA-Z][a-zA-Z0-9]*".
- word_bound_right
-
append \b to the end of keyword pattern. It should let regex perform word bound on right matching.
word(word_bound_right) should generate r"[a-zA-Z][a-zA-Z0-9]*\b".
- word_bound
-
enclose \b around keyword pattern. It should let regex perform word bound on matching.
word(word_bound) should generate r"\b[a-zA-Z][a-zA-Z0-9]*\b".
- head
-
prepend ^ to keyword pattern which inform regex engine that pattern should start at the beginning of string.
word(head) should generate r"^[a-zA-Z][a-zA-Z0-9]*".
- head_ws
head_whitespace -
prepend ^\\s* to keyword pattern which inform regex engine that pattern should start at the beginning of string with zero or some whitespaces.
word(head_whitespace) should generate r"^\s*[a-zA-Z][a-zA-Z0-9]*".
- head_ws_plus
head_whitespaces
head_whitespace_plus -
prepend ^\\s+ to keyword pattern which inform regex engine that pattern should start at the beginning of string with some whitespaces.
word(head_whitespaces) should generate r"^\s+[a-zA-Z][a-zA-Z0-9]*".
- head_space
-
prepend ^ * to keyword pattern which inform regex engine that pattern should start at the beginning of string with zero or some blank-space.
word(head_space) should generate r"^ *[a-zA-Z][a-zA-Z0-9]*".
- head_spaces
head_space_plus -
prepend ^ + to keyword pattern which inform regex engine that pattern should start at the beginning of string with some blank-space.
word(head_spaces) should generate r"^ +[a-zA-Z][a-zA-Z0-9]*".
- head_just_ws
head_just_whitespace -
prepend \\s* to keyword pattern which transform to match zero or some whitespaces and then pattern.
word(head_just_whitespace) should generate r"\s*[a-zA-Z][a-zA-Z0-9]*".
- head_just_ws_plus
head_just_whitespaces
head_just_whitespace_plus -
prepend \\s+ to keyword pattern which transform to match some whitespaces and then pattern.
word(head_just_whitespaces) should generate r"\s+[a-zA-Z][a-zA-Z0-9]*".
- head_just_space
-
prepend * to keyword pattern which transform to match zero or some blank-space and then pattern.
word(head_just_space) should generate r" *[a-zA-Z][a-zA-Z0-9]*".
- head_just_spaces
head_just_space_plus -
prepend + to keyword pattern which transform to match some blank-space and then pattern.
word(head_just_spaces) should generate r" +[a-zA-Z][a-zA-Z0-9]*".
- tail
-
append $ to keyword pattern which inform regex engine that stop matching after seeing pattern.
word(tail) should generate r"[a-zA-Z][a-zA-Z0-9]*$".
- tail_ws
tail_whitespace -
append \\s*$ to keyword pattern which inform regex engine that stop matching after seeing pattern and zero or some whitespaces.
word(tail_whitespace) should generate r"[a-zA-Z][a-zA-Z0-9]*\s*$".
- tail_ws_plus
tail_whitespaces
tail_whitespace_plus -
prepend \\s+$ to keyword pattern which inform regex engine that stop matching after seeing pattern and some whitespaces.
word(tail_whitespaces) should generate r"[a-zA-Z][a-zA-Z0-9]*\s+$".
- tail_space
-
prepend *$ to keyword pattern which inform regex engine that stop matching after seeing pattern and zero or some blank-space.
word(tail_space) should generate r"[a-zA-Z][a-zA-Z0-9]* *$".
- tail_spaces
tail_space_plus -
append +$ to keyword pattern which inform regex engine that stop matching after seeing pattern and some blank-space.
word(tail_spaces) should generate r"[a-zA-Z][a-zA-Z0-9]* +$".
- tail_just_ws
tail_just_whitespace -
append \\s* to keyword pattern which transform to match pattern and then zero or some whitespaces.
word(tail_just_whitespace) should generate r"[a-zA-Z][a-zA-Z0-9]*\s*".
- tail_just_ws_plus
tail_just_whitespaces
tail_just_whitespace_plus -
append \\s+ to keyword pattern which transform to match pattern and then some whitespaces
word(tail_just_whitespaces) should generate r"[a-zA-Z][a-zA-Z0-9]*\s+".
- tail_just_space
-
append * to keyword pattern which transform to match pattern and zero or some blank-space.
word(tail_just_space) should generate r"[a-zA-Z][a-zA-Z0-9]* *".
- tail_just_spaces
tail_just_space_plus -
append + to keyword pattern which transform to match pattern and then some blank-space.
word(tail_just_spaces) should generate r"[a-zA-Z][a-zA-Z0-9]* +".
- ?
-
To Be Announced
letter(var_v1, ?) should generate r"(?P<v1>[a-zA-Z]?)".
- *
-
To Be Announced
letter(var_v1, *) should generate r"(?P<v1>[a-zA-Z]*)".
- +
-
To Be Announced
letter(var_v1, +) should generate r"(?P<v1>[a-zA-Z]+)".
- {k}
-
To Be Announced
letter(var_v1, {0) should generate r"(?P<v1>[a-zA-Z]?)".
letter(var_v1, {1) should generate r"(?P<v1>[a-zA-Z])".
letter(var_v1, {5) should generate r"(?P<v1>[a-zA-Z]{5})".
- {m,n}
-
To Be Announced
letter(var_v1, {,5) should generate r"(?P<v1>[a-zA-Z]{,5})".
letter(var_v1, {2,) should generate r"(?P<v1>[a-zA-Z]{2,})".
letter(var_v1, {2,5) should generate r"(?P<v1>[a-zA-Z]{2,5})".
- phrase?
group? -
To Be Announced
letters(var_v1, phrase?) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+)?)".
letters(var_v1, group?) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+)?)".
- phrase*
group* -
To Be Announced
letters(var_v1, phrase*) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+)*)".
letters(var_v1, group*) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+)*)".
- phrase+
group+ -
To Be Announced
letters(var_v1, phrase+) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+)+)".
letters(var_v1, group+) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+)+)".
- phrase{k}
group{k} -
To Be Announced
letters(var_v1, phrase{0}) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+)?)".
letters(var_v1, group{0}) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+)?)".
letters(var_v1, phrase{1}) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+))".
letters(var_v1, group{1}) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+))".
letters(var_v1, phrase{5}) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+){5})".
letters(var_v1, group{5}) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+){5})".
- phrase{m,n}
group{m,n} -
To Be Announced
letters(var_v1, phrase{2,}) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+){2,})".
letters(var_v1, group{2,}) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+){2,})".
letters(var_v1, phrase{,5}) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+){,5})".
letters(var_v1, group{,5}) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+){,5})".
letters(var_v1, phrase{2,5}) should generate r"(?P<v1>[a-zA-Z]+( [a-zA-Z]+){2,5})".
letters(var_v1, group{2,5}) should generate r"(?P<v1>[a-zA-Z]+( +[a-zA-Z]+){2,5})".
- or_space?
or_ws?
or_whitespace?
or_either_space?
or_either_ws?
or_either_whitespace? -
To Be Announced
letters(var_v1, or_space?) should generate r"(?P<v1>( ?)|([a-zA-Z]+))".
letters(var_v1, or_whitespace?) should generate r"(?P<v1>(\s?)|([a-zA-Z]+))".
letters(var_v1, or_either_space?) should generate r"(?P<v1>( ?)|( *[a-zA-Z]+ *))".
letters(var_v1, or_either_whitespace?) should generate r"(?P<v1>(\s?)|( *[a-zA-Z]+ *))".
- or_space*
or_ws*
or_whitespace*
or_either_space*
or_either_ws*
or_either_whitespace* -
To Be Announced
letters(var_v1, or_space*) should generate r"(?P<v1>( *)|([a-zA-Z]+))".
letters(var_v1, or_whitespace*) should generate r"(?P<v1>(\s*)|([a-zA-Z]+))".
letters(var_v1, or_either_space*) should generate r"(?P<v1>( *)|( *[a-zA-Z]+ *))".
letters(var_v1, or_either_whitespace*) should generate r"(?P<v1>(\s*)|( *[a-zA-Z]+ *))".
- or_space+
or_ws+
or_whitespace+
or_either_space+
or_either_ws+
or_either_whitespace+ -
To Be Announced
letters(var_v1, or_space+) should generate r"(?P<v1>( +)|([a-zA-Z]+))".
letters(var_v1, or_whitespace+) should generate r"(?P<v1>(\s+)|([a-zA-Z]+))".
letters(var_v1, or_either_space+) should generate r"(?P<v1>( +)|( *[a-zA-Z]+ *))".
letters(var_v1, or_either_whitespace+) should generate r"(?P<v1>(\s+)|( *[a-zA-Z]+ *))".
- or_space{k}
or_ws{k}
or_whitespace{k}
or_either_space{k}
or_either_ws{k}
or_either_whitespace{k} -
To Be Announced
letters(var_v1, or_space{5}) should generate r"(?P<v1>( {5})|([a-zA-Z]+))".
letters(var_v1, or_whitespace{5}) should generate r"(?P<v1>(\s{5})|([a-zA-Z]+))".
letters(var_v1, or_either_space{5}) should generate r"(?P<v1>( {5})|( *[a-zA-Z]+ *))".
letters(var_v1, or_either_whitespace{5}) should generate r"(?P<v1>(\s{5})|( *[a-zA-Z]+ *))".
- or_space{m,n}
or_ws{m,n}
or_whitespace{m,n}
or_either_space{m,n}
or_either_ws{m,n}
or_either_whitespace{m,n} -
To Be Announced
letters(var_v1, or_space{2,}) should generate r"(?P<v1>( {2,})|([a-zA-Z]+))".
letters(var_v1, or_whitespace{2,}) should generate r"(?P<v1>(\s{2,})|([a-zA-Z]+))".
letters(var_v1, or_either_space{2,}) should generate r"(?P<v1>( {2,})|( *[a-zA-Z]+ *))".
letters(var_v1, or_either_whitespace{2,}) should generate r"(?P<v1>(\s{2,})|( *[a-zA-Z]+ *))".
letters(var_v1, or_space{,5}) should generate r"(?P<v1>( {,5})|([a-zA-Z]+))".
letters(var_v1, or_whitespace{,5}) should generate r"(?P<v1>(\s{,5})|([a-zA-Z]+))".
letters(var_v1, or_either_space{,5}) should generate r"(?P<v1>( {,5})|( *[a-zA-Z]+ *))".
letters(var_v1, or_either_whitespace{,5}) should generate r"(?P<v1>(\s{,5})|( *[a-zA-Z]+ *))".
letters(var_v1, or_space{2,5}) should generate r"(?P<v1>( {2,5})|([a-zA-Z]+))".
letters(var_v1, or_whitespace{2,5}) should generate r"(?P<v1>(\s{2,5})|([a-zA-Z]+))".
letters(var_v1, or_either_space{2,5}) should generate r"(?P<v1>( {2,5})|( *[a-zA-Z]+ *))".
letters(var_v1, or_either_whitespace{2,5}) should generate r"(?P<v1>(\s{2,5})|( *[a-zA-Z]+ *))".
How Does It Work?